What is Barlo?
Barlo.dog is a platform in development that helps connect people wanting to foster or adopt rescue dogs. The problem that these people have are the vast array of charities across the UK that need to be searched to find a dog that matches your lifestyle and needs.

Data Pipelines
As a starting point, the objectives for Barlo’s data pipelines were simply the following:
- Provide an up-to-date repository of rescue dogs that the API can serve
- For the data provided to be clean, consistent and traceable through the system no matter the source.
Data Discovery
First of all, we needed to find some sources to pull data about rescue dogs in the UK.
The first immediate solution to this was to scrape the data from different charity sites that provide lists of the dogs up for adoption.
Whilst this isn’t ideal, I designed the code to be as scalable as possible when more dog charities are onboarded.
The other option is to work with companies that provide Animal rescue / shelter software, and tap the source of the information.
Luckily, one provider called Animal Shelter Manager provides an API that we could use from the get go to potentially onboard 156 charities!
Now we have 2 different types of sources:
- API
- Web Scraping
High-Level Data Diagram
Our pattern for moving data into the right place on Barlo is ELT. Extract Load Transform ensures we move the data from source to target first, before performing any transformations on the data.
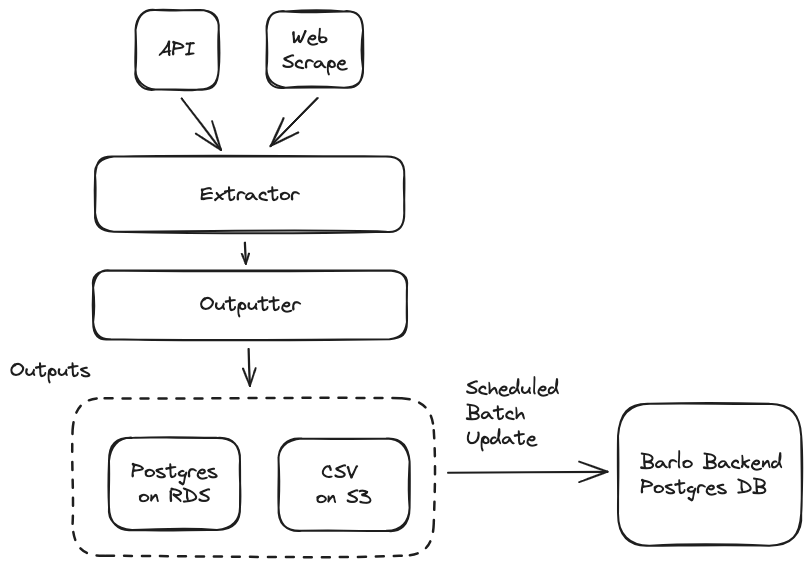
Extractors and Outputters
I designed two Python classes to help with taking data from a source and sending it to a target.
The Extractor gives us a common way of picking up data from either an API or Web Scraping source.
The Outputter gives us a common way to write an Extractor output to any sort of target.
Outputs
Currently, data is written daily into a Postgres table, and CSVs on S3. This allows for more options moving forward with how we want to ingest the data downstream.
Scheduled Batch Update
Once the dog data 🐕 is fully loaded into our target, there are daily jobs that clean, transform and write the data into a usable format that the Barlo API can use. This API only serves the latest information about our dogs, so whilst the data dumps will have historical information, this final table will just have the latest information about adoptable dogs on Barlo.
Infrastructure Used
Extract & Load — AWS Lamba
The code for web scraping, and extracting data from APIs is all executed via AWS lambda. Lambda allows us to extract and write data in an entirely serverless manner, avoiding the need to manage any infrastructure ourselves, all whilst keeping costs pretty low.
We did look at using some some data extraction tools like FiveTran/Hevo. Lambda also allows us to schedule the jobs so that we have have fresh data every day. We can increase the cadence of these jobs in the future.
Data Targets — AWS RDS & S3
One of our targets when writing 🐕 data is Postgres. We’re creating and managing this database via Amazon’s Relational Database Service.
The other target is Amazon’s Simple Storage Service. As well as writing to the Postgres instance, CSV files are written into S3 with every job.
Transformations — DBT
For cleaning and transforming data we decided to use Data Build Tool. This tool lets developers design and implement data pipelines all using SQL, relying on the database’s engine to execute all the transformation queries.
Future Development
Moving forward, we want to let charities submit their adoptable dogs via Excel / CSV, so we will need to add a new Extractor to allow that.